Reduce, Re-use, We’re Not Talking About Recycling Here.
October 27, 2009
So your business is green now… how about your website?
Imagine if you printed each page of your site, and then gave them to Google. Then, after you handed them over, Google had to file them away in their archives. The smaller the pages are, the less space your pages would take up, correct?
If we look back at rule no. 1 of the Three Golden Rules Of SEO: “Do right to Google and Google will do right to you,” we uncover a great SEO rule for techs: the more we can reduce the size of the pages on a website, the better the website is for Google to crawl.
So - how do I reduce the size of my pages and my site?
Removing on-page CSS and Javascript and placing them in external files.
Reusing the same style sheet and javascript file will make your site easier to update and also more consistent. This will also reduce the total number of bytes the page contains when Google has to index it. In order to do this, you would need to edit the pages of your site and move the code into a seperate file.
Given the sample below, PennDOT has 87 lines of javascript on their home page. They could copy and paste that code into a file called home-page.js and replace all those lines of code with 1 line.
<script src=”/home-page.js” language=”JavaScript” type=”text/javascript”></script>
For moving CSS, it is the same approach but the code is slightly different. Take a look at the 300+ lines of CSS on the Lancaster County Library website. This can be easily moved to an external style-sheet by copying and pasting that code into a file named home-style.css and replaced with 1 line in the head section as follows:
<link href=”/home-style.css” rel=”stylesheet” type=”text/css” />
You’re welcome Google, we just saved you 8KB of bandwidth and 8KB of storage each time you index those two pages!
No-Index duplicate pages with robots.txt
Create a file in the main directory of your website named “robots.txt”. The search engines will read this file each time it crawls your site to see what urls you don’t want included in the index. To determine what urls to exclude, you could do a Google search using “site:yourdomain.com” and look at the results.
If you have a lot of duplicate pages, especially from a dynamically generated script, the results will most likely be displayed at the end of the results. Click to the end of the pages of results, and look for the caption at the end “In order to show you the most relevant results, we have omitted some entries very similar to the X already displayed.”

If you like, you can repeat the search with the omitted results included. Click on that link and browse through the duplicate results. Once you have determined some urls to exclude you would simply add them to the robots.txt one url per line, as follows:
User-agent: *
Disallow: /url-to-block
The search engine spiders support blocking an entire directory as follows:
User-agent: *
Disallow: /directory-to-block/
Googlebot specifically supports a wild card feature. So if you would like to block an entire range of urls, say from a web calendar at an address like /calendar-2009.html you could do this as follows:
User-agent: googlebot
Disallow: /calendar-*.html
See if your web server supports the If-Modified-Since HTTP headers
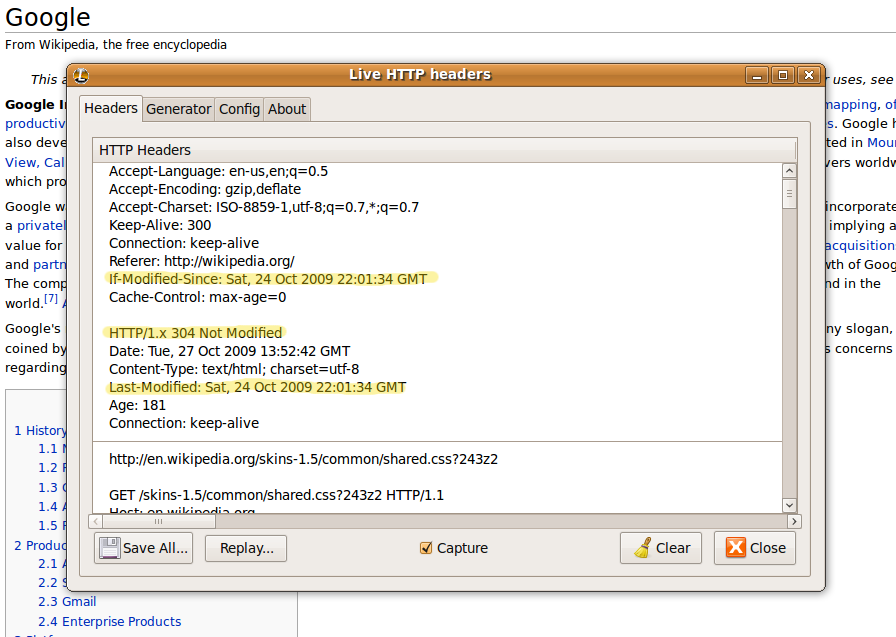
I use a Firefox plugin called Live HTTP Headers so that I can inspect the http server headers. This is a handy troubleshooting tool while testing 301 redirects as well.
In order to use this you would need to be using Firefox, and install the plugin. Go under the tools menu and choose “Live HTTP Headers.” Leave the box open and load your website in the browser.
Several lines of text will go whizzing past. Go the whole way up to the top to look at the original request and response. Note the headers for a page from Wikipedia in the image below. In the first section - “GET /wiki/Google HTTP/1.1” - is the request that the browser sent to the server. Note the line “If-Modified-Since.” This second section is the response from the server. What we are looking for here is the first line “HTTP/1.x 304 Not Modified” and “Last-Modified: Sat, 24 Oct”… This server does support the If-Modified-Since HTTP header.
When the Googlebot spiders this page again, it will be able to determine if the current web page is newer then the one already in the Google cache, therefore saving bandwith to download the page and storage space to store duplicate pages.

By Ashley Walter, Director of Operations
Ashley Walter is ProspectMX's Marketing Operations Manager. With a BS in International Business and concentrations in Marketing and Spanish, Ashley uses her knowledge in these industries to manage every aspect of a client's campaign. Before coming to work full-time at ProspectMX, she held an internship with us and demonstrated remarkable skill and knowledge in the internet marketing field. Creative, meticulous, and hardworking, Ashley is the go-to girl for ProspectMX and can handle any task or situation that is thrown at her.